To guide this part of the conversation, we’re going to draw heavily from the analysis of the manufacturing supply chain in part 1, and Deming’s four principles that apply to both regular and software supply chains.
So, let’s quickly recap that and how it relates to software development:
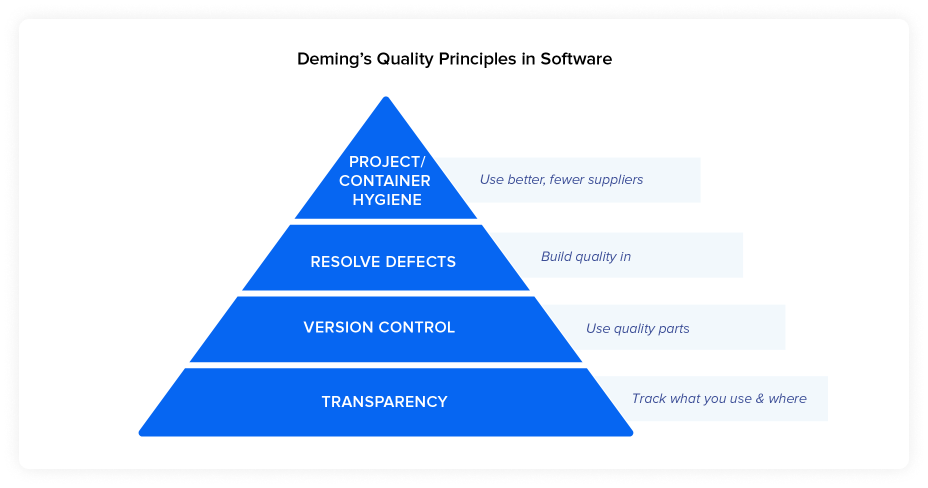
Now we’ll explain how it maps back to the software development process
The industry and the world are coming to terms with the volume of consumption and the massive ecosystem of suppliers you can source your components from. While some manual review is likely to always remain in part, the stark volume of artifacts would outpace any attempt to manually review them to determine their health. No matter what part of the software supply chain you’re looking at, addressing the issues at scale requires automation. Any organization hesitating to embrace these practices is likely to fall behind.
Just as traditional manufacturing supply chains have turned to automation, software development teams need to take the same approach. Information about suppliers and the quality and security of their projects needs to be made available to developers at the time they are selecting components, continuously throughout the lifecycle of development and updated consistently once the application is in production.
Automation in areas of testing, build, and deployment has provided significant performance benefits. Likewise, investments in software supply chain automation have shown markedly improved efficiency and controlled risk. Automation can unleash the potential of an organization’s development capacity. Rarely is there such an opportunity to simultaneously increase speed, efficiency, security, and quality
No matter what part of the software supply chain you’re looking at, addressing the issues at scale requires automation.
Like in traditional manufacturing, not all suppliers deliver parts of comparable quality and integrity. Research shows that some open source projects use restrictive licenses and vulnerable sub-components, and some projects are far more diligent at updating the overall quality of their components. Yet little understanding is often given to who is actually creating the open source components a developer is about to use.
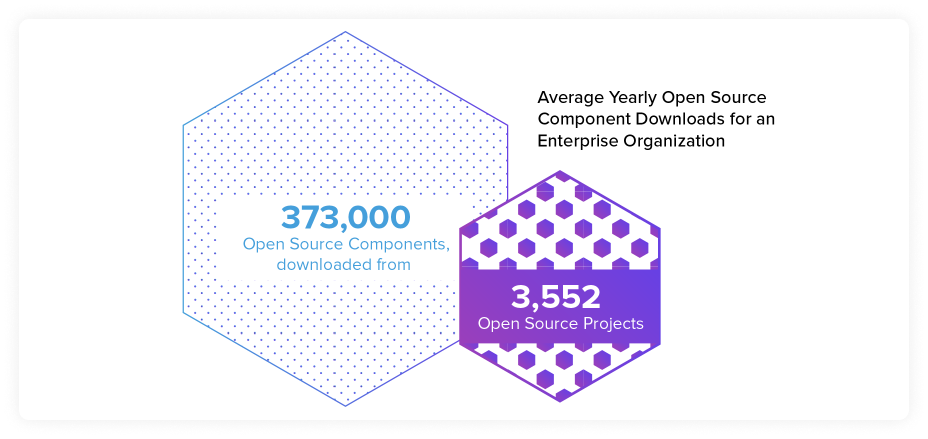
Further, the number of suppliers organizations are pulling components from is daunting. In the 2020 State of the Software Supply Chain report, we found that enterprise development organizations, on average, downloaded 373,000 open source components a year, and the downloads represented an average of 3,552 open source projects (or suppliers).
Last but not least, unlike physical suppliers being used within traditional supply chains, once an open source project is made available, it is never taken out of circulation. This means developers can inadvertently continue to use the old, outdated projects - even some who have been completely abandoned by their maintainers.
Some consideration about the teams behind those projects can save a lot of time and effort down the road.
Choosing an open source project supplier should be considered an important strategic decision in organizations. Changing a supplier (an open source project) is far more effort than swapping out a specific component. Like traditional suppliers, open source projects have good and bad practices that impact the overall quality of their component parts.
Traditional manufacturing supply chains intentionally select specific parts from approved suppliers. They also rely on formalized sourcing and procurement practices. This practice also focuses the organization on using fewer suppliers.
Bringing this practice to development improves quality, with less developer “context switching,” or continuously jumping between tasks. Developers can give fewer topics better focus. This also accelerates mean time to repair when defects are discovered.
By contrast, development teams often rely on an unchecked variety of supply, where each developer or development team can make their own sourcing and procurement decisions. The effort of managing those 3,552 suppliers mentioned above introduces a drag on development. It's contrary to their need to develop faster as part of agile, continuous delivery, and DevOps practices.
Many teams aim for software projects that their teams are familiar with or that represent the most popular project in a given category. Analysis of suppliers in our 2021 report indicated that popularity was a poor indicator of quality, with 29% of popular projects containing at least one known security vulnerability. Projects with lower popularity had on average 6.5%. Whether this was due to attention paid by security researchers or other factors, the wide difference demands more analysis.
An analysis of popular suppliers in 2021 indicated that popularity was a poor indicator of quality.
Our insights suggest there are a few key indicators to chase, including:

These attributes can simplify your search for higher quality open source software projects and will drastically increase the hygiene of your software supply chain decreasing technical debt and innovation tax.
WHAT TO LOOK FOR: Projects maintained by a group of engaged and responsive developers; has a clear and substantive set of contribution guidelines; and has an active community whose members contribute regularly to improve the source code.
BE LEERY OF: Projects haven’t been updated in a few years, especially that have only one or two maintainers that don’t really engage with users or without invitations for involvement. A project with a single commit might solve a short-term problem but could be cause for serious concern in the long term.
Now that you’ve picked a supplier, it might make it seem like you’ve done most of the hard part. Just as machines made with high and low quality parts have good or poor outcomes, some components are better than others - even from high quality suppliers.
While some in the industry have talked about this as “version control,” we often use the term "dependency management" (specifically micro dependency management, but we’ll unpack all of that at a later date).
There are three reasons why dependency management (or version control) is becoming an increasingly important practice for managing software supply chains:
The average modern application contains 128 open source dependencies, and the average open source project releases 10 times per year. This creates a daunting task for teams, and again becomes a reminder of how automation is vital.
The average modern application contains 128 open source dependencies, and the average open source project releases 10 times per year, creating a daunting task for teams.
To help understand how to select, and continue to choose, the optimal parts to use in your software supply chain, we came up with 8 general rules. These all build upon each other and follow below:
As we said above, these 8 rules build on each other.

The latest version is not always an improvement
In an attempt to help automate dependency management decision making, some engineering teams have chosen tools that simply grab the latest version of a part, as soon as it becomes available. This is a short-sided view that new = best quality.
These updates can have unintended consequences like the introduction of unplanned work and unnecessary security risk – e.g. malware injection and namespace confusion. This type of naive dependency update strategy can lead to frustration and distraction. According to the 2021 State of the Software Supply Chain Report, the optimal version is on average, 2.7 versions from the LATEST version. This highlights how the most recent release is not always the best choice and underscores why well thought-out policies are needed around dependency management, rather than the path of least resistance.
The most common problems with keeping only the best parts within your supply chain come from those transitive dependencies, nestled deep within components, that are so hard to see. We’ll talk more about how to create the transparency needed next, as well as the automation techniques that help not only provide transparency, but the appropriate hygiene, maintainability, and integrity.
The most common problems with keeping only the best parts within your supply chain come from transitive dependencies, nestled deep within components, that are so hard to see.
Repository managers serve as a local warehouse for all your open source and InnerSource software components. They’re also a fundamental first step toward dependency management as part of your broader software supply chain management. By housing components locally, development teams have more efficient and controlled component access across an organization. Repository managers are used to streamline the acquisition, consumption, sharing, and deployment of components downloaded from public repositories, as well as other internal build components and artifacts.
Once components are cached in a repository manager, developers and their development tools can retrieve the component locally as many times as necessary across the organization, regardless of the number of applications needing it. Repository managers support the concept of download-once-use-many-times that improves sourcing practices. It is therefore a foundational step in improving performance and control of components or parts across the software supply chain.

Whatever else happens to the software supply chain in the next decade and beyond, it’s likely that developers will continue to assemble and maintain components. How companies differentiate themselves and their product begins at this stage, with developers connecting the various component parts we’ve been talking about, and writing unique code. This “first party” source code work is where your company begins solving customer problems.
Most tools in this space are designed to help with “Agile” development requirements, with an intense focus on the customer and their needs. Successful projects are usually evaluated by looking at whether or not it answers customer requirements and requests. But what about features common to all software projects like reliability, speed, and security?
When development teams focus on anything from code readability, responsiveness, maintainability, reliability, etc. they are talking about code quality.
This “first party” source code work is where your company begins solving customer problems.

Automatable code quality
Many factors play into automation: architecture, API design, coding style, library choice, and following coding best practices are just a few examples. While some of these like architecture and design require human insight, others can be automated using code analysis tooling. Tooling can be a great way to ensure uniform standards and incorporate analysis tools into the development process, and is an easy first step down the road of prioritizing quality.
The components you select from the software supply chain aren’t worthwhile if your first party code isn’t using them effectively. Code quality tools can enable better development at scale, and help manage interactions with third-party software that create problems for your software. This includes API best practices, information flow, and common implementation errors for cryptography libraries.
Although shorthand in our industry puts open source components “upstream” and end-users of the software “downstream,” it can also refer to tasks long before testing. Teams must also avoid passing known defects within their own company, whether to security, operations, or even other developers and - most importantly - not to production applications.
Passing problematic software or frequent workarounds for buggy tools is another form of technical debt. Over time, this debt must be paid in the form of rework and refactoring, usually unplanned and unwelcome.
No software is bug-free so teams must use their best judgment, but rarely err on the side of caution. When restricted by limited resources or tight deadlines, groups will allow major issues to pass on to the next stage of the software supply chain.
Passing problematic software or frequent workarounds for buggy tools is another form of technical debt.
Much of this document seeks to understand and optimize how external software dependencies work. Equally important is the notion of who handles the results of that management: your internal staff. While it may vary between organizations, the majority of teams have three specialized groups:
These are the people who assemble, test, and deliver software products for your organization. An ongoing effort in the 2000s to improve agility and responsiveness put attention on the silos and bottlenecks between departments. Streamlining this work meant creating more overlap between development and operations, a concept broadly described as “DevOps.”
As noted by Forrester Research about DevOps practices:
DevOps provides the objective information — and visibility into that information — that organizations need to make application delivery decisions. In place of periodic, subjective, and time-consuming status reports, firms get real- time insight into application health and delivery progress, gathered as a natural part of the work that teams do.
— FORRESTER RESEARCH
The success of this concept and its value has also meant reduced silos for security, previously seen as a blocker or goalkeeper, to create “DevSecOps.”
While we cannot hope to address all the ways in which a DevOps approach can improve your software supply chain management, there are available resources.
A central pillar of DevOps and DevSecOps is “Shift Left”, also called “Start Left”. This phrase describes the principle of testing and checking code quality early in the Software Development Life Cycle (SDLC).
Put simply, the easiest way to pass better quality software downstream is to not push off testing until the end of a process. Since most descriptions of software development processes are written in diagrams structured from right-to-left, moving from late to early in the process means shifting them to the left.
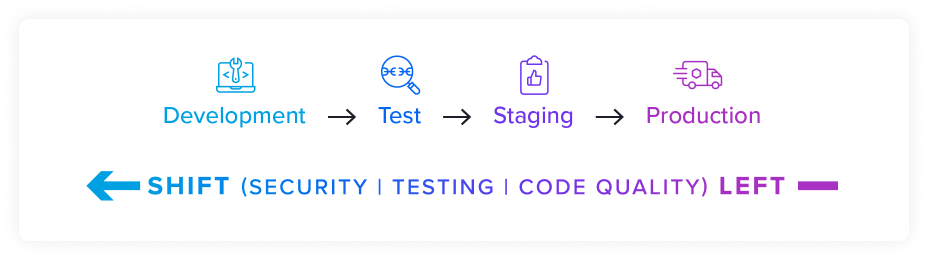
While every development team is different and each process is unique, the goal is to avoid making testing and security tasks a kind of gate before software can move on to the next step. Making these tasks part of the process is one of the primary goals of movements in DevOps, DevSecOps, and Continuous Integration / Continuous Delivery.
While the term “shift left” has come to be a kind of buzzword catch-all for generally faster development practices, the goal is to better position developers, who are often on the front lines of quality, security, and operations.
What Sonatype means when we say “shift left” is answering Demming’s guidance: “you can’t inspect quality into your products.” You have to start at the beginning.
There are a variety of ways that organizations can track their component software, automation and standardizations have appeared in this space. Just like regular suppliers have a bill of materials that can be audited during a product recall, software has an option available for audits and more.
Readers looking for a way to address software supply chain issues should start here. After all, you can’t do anything without knowing what’s in your software. As Gartner research said:
“To manage and mitigate the risk of open-source software, security and risk management leaders responsible for the security of applications and data must continuously build a detailed software bill of materials (BOM) for each application providing full visibility into components.” - Gartner, 2019
The problem, ultimately, is that while an open source maintainer can issue a quick and “easy” fix to a vulnerability, the sheer ubiquity of a software component across cloud services, applications, and infrastructure can make it incredibly difficult to deploy an update quickly enough. But more than that, they might not even know that their software contains that component in the first place. And if they don’t know, how can they remedy it?
— VENTUREBEAT
What is a Software Bill of Materials?
A bill of materials (BOM) tracks components, parts, and raw materials present in items like cars, electronics, and food products. BOMs essentially serve as a production roadmap, detailing every component’s journey across the supply chain.
By using a BOM, a company can quickly identify and remediate production issues. For example, when a defective Takata airbag was found back in 2016, car manufacturers were able to track all affected vehicles thanks to the record of parts contained in the BOM. With this data, manufacturers could quickly see a list of affected parts and issue a recall alert.
BOMs improve safety and performance and expedite issue resolution.
In short, BOMs improve safety and performance and expedite issue resolution. And all of these facets are aligned with software development.
How BOMs Apply to Software Engineering
As we’ve been discussing, most software today contains a complex array of components, both proprietary and open source. When working with a complicated set of parts, it’s critical to keep a running list of all items and source locations. Otherwise, you’ll have a much harder time monitoring the components you’re using, which can result in outdated or insecure code.
A software bill of materials (SBOM) is a list of ingredients (components) that make up a software application. Key information includes component names, license information, version numbers, and vendors. This reduces risk for both the producer and consumer by providing a formal list of all details that enables others to understand what’s in their software and act accordingly.

While an SBOM can’t prevent undiscovered vulnerabilities, it can surface issues earlier in the process and help reduce the chance they end up in your software. And, because a supply chain is only as strong as its weakest link, unseen software vulnerabilities can lead to a costly breach.

Are SBOMs catching on?
Many organizations still don’t have a full picture of what’s inside their software and some aren’t even looking. As of 2020, fewer than 50% of companies produce SBOMs as a standard practice in software development.
But that’s changing with increased software purchasing requirements. A growing number of organizations are either requesting or requiring an SBOM when buying and integrating software. According to Garner research:
By 2025, 60% of organizations building or procuring critical infrastructure software will mandate and standardize SBOMs in their software engineering practice, up from less than 20% in 2022. By 2024, 90% of software composition analysis tools will be able to generate and verify SBOMs to help securely consume open-source software, up from 30% in 2022.”
— GARTNER RESEARCH, AS REPORTED BY SECURITY BOULEVARD
In particular, the creation and maintenance of an SBOM is becoming a requirement of sales to the U.S. Federal government. In May 2021, President Joe Biden issued an Executive Order focused on improving the nation’s cybersecurity stance. The order tasks the Commerce Department and the National Telecommunications and Information Administration (NTIA) with publishing minimum SBOM requirements to secure the software supply chain.
Not having an SBOM means that companies are blind to known-vulnerable open source components being shipped in their software applications.
Further, without an SBOM, these same companies are guaranteed to struggle, much like Equifax did in 2017, to respond to new zero day vulnerability disclosures in open source components. And, the thousands of companies still struggling with the recent Log4j and Spring4Shell vulnerabilities. With 10,000+ vulnerabilities announced annually, there are 10,000 very good reasons to have an SBOM for all of your production applications.
With 10,000+ vulnerabilities announced annually, there are 10,000 very good reasons to have an SBOM for all of your production applications.
Development and security groups need speed, accuracy, and precision. The more you can identify all of the open source components in an application quickly and precisely, the more you can avoid false positives and false negatives common in other methodologies and enable a mature Software Composition Analysis solution in the DevOps environment. While parts of SCA may help with the other steps in software supply chain management, we’ve chosen to keep the bulk of the conversation in our section on transparency to help sum it all up.
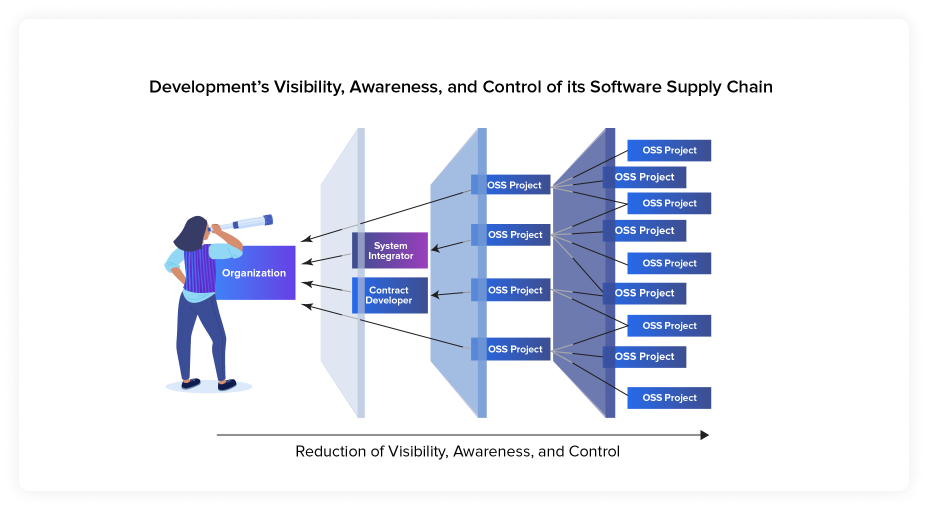
SCA is about looking at all the components in a project and determining the potential risk (mostly security risk) from those components. This type of analysis is done using tools to find and identify risk in your applications. These tools can be automated and monitor components across the entire Software Development Lifecycle (SDLC).
Automated malware detection and reacting to vulnerable components
The later a vulnerability is found, the more time and effort it takes to resolve. Any components in your software might be affected by a discovered vulnerability at any stage. Employing precise vulnerability data as early as possible in the process means better control over your software supply chain. Fewer false positives and false negatives are the best measure of accuracy and completeness.
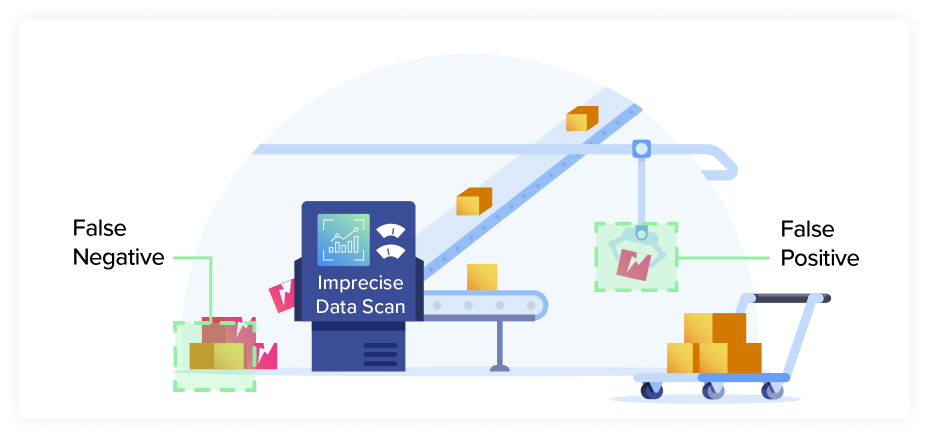
Most testing and analysis tools have the difficult task of delivering the right information at the right time, and this is even more true of SCA software. Teams that need to scale have to escape a more-is-better mentality.
For example, getting 10 notifications about various Log4j instances and versions in your environment is wasteful if teams have already upgraded all versions. You only need a single warning and that warning should disappear after the update is applied (and your SCA tool has verified it).

Ready to Try Nexus Products?





